


În zilele mohorâte din ianuarie, când gradele erau cu minus, iar dorința mea de a ieși din casă era aproape inexistentă, mintea a-nceput să-mi zboare la locuri mai calde, cu un aer ceva mai primăvăratic decât cel din București. Începusem să mă gândesc la toate țările de pe lista mea, cu o vreme ceva mai călduroasă, unde aș putea organiza un city break. Deoarece eram din ce în ce mai entuziasmată de acest gând, de plecat, de mers oriunde aș putea găsi măcar 10 grade plus, am început să caut cazări pe AirBnB în Malta. Și, cu ajutorul acestui context, mi-a venit ideea să lucrez la un nou proiect în Python: analiza review-urilor de pe AirBnB pentru cazările din Malta.
Deci, dacă vei avea puțină răbdare să parcurgi cu mine această analiză, vei putea și tu la final să aplici ce ai învățat aici, de la 0, noțiunile legate de NLP pe propriul tău proiect (ai și codul complet atașat la final). Și, pentru că este deja al doilea paragraf și eu tot nu m-am prezentat, vreau doar să-ți zic că eu sunt Diana, lucrez ca Data Scientist și acesta este al doilea articol scris pentru comunitatea 4Mayo (posibil să fi citit primul meu articol sau să fi discutat deja pe LinkedIn cu mine). Și acum să începem.
Ce este NLP?
Nu știu dacă pentru tine este prima dată când auzi de conceptul de NLP (Natural Language Processing), însă pentru mine a fost prima dată când l-am testat într-un proiect. Natural Language Processing reprezintă procesul prin care putem analiza diverse texte începând de la articole, cărți, postări pe Twitter, Instagram, recenzii de filme sau, în cazul de față, feedback-ul clienților de pe AirBnB. Deoarece informația este una nestructurată, oamenii au lucrat la diverse funcții pentru a desluși cuvintele și înțelesul din spatele lor. Unul dintre cele mai populare pachete în Python este NLKT (natural language toolkit), pe care îl voi folosi și eu în următoarele paragrafe. Ca și proiecte, NLP te poate ajuta să: diferențiezi e-mailurile importante de cele spam, analizezi sentimentele (feedback negativ/pozitiv/neutru), creezi un rezumat, identifici subiectul dintr-un articol/carte, lucrezi la un ChatBot, autocorectezi cuvintele sau să autocompletezi enunțurile.
1. Setul de date – AirBnB Malta
Pentru o imagine mai clară, voi începe prin a descrie puțin setul de date cu care vom lucra. Deși nu am găsit un API public pentru AirBnB (este nevoie de o cerere oficială către ei pentru a-ți permite accesul), am reușit să descarc datele de pe acest website. La momentul în care am descărcat fișierele csv, acestea fuseseră actualizate ultima dată pe 28 Decembrie, 2021. Aici am găsit informații atât despre cazări, cât și despre review-uri, în fișiere separate. Mai jos putem vedea cum arată tabelul cu comentarii:
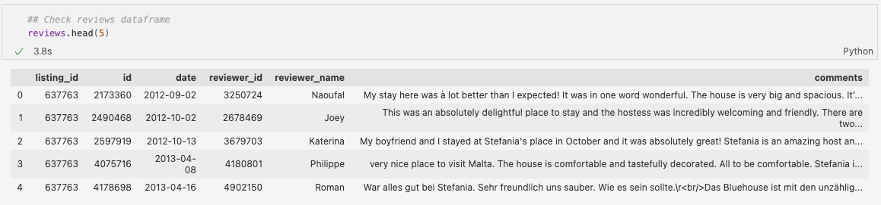
După cum se observă, avem un ID unic pentru fiecare comentariu, dar și unul ce ne ajută să conectăm acest tabel cu cel principal (ce conține mai multe detalii legate de cazare), data la care a fost postat, ID-ul și numele persoanei care l-a scris și, coloana cea mai interesantă pentru noi, review-urile în forma lor brută – 173180 de comentarii, mai precis.
Să aruncăm o privire la un feedback ceva mai lunguț:

Bun, acest review conține 946 de cuvinte. Ca idee, media numărului de cuvinte într-un comentariu este de 52, deci persoana de mai sus a încercat să descrie cât mai bine experiența, oferind informații atât despre cameră, locație, transport, dar și gazdă. Mai jos se vede cum am calculat numărul de cuvinte pentru toate textele și am salvat rezultatul în coloana words. Am renunțat apoi la acele comentarii care conțineau doar o literă, ele nefiind relevente:

2. Curățarea textului
Pentru a începe analiza, mai întâi am transformat coloana comentariilor în tip ‘string’(caracter). Am început să-mi curăț datele, fapt ce a constat în mai mulți pași:
- Eliminarea comentariilor nule, dacă existau.
- Toate cuvintele le-am modificat astfel încât să conțină doar litere mici.
- Am eliminat numerele din comentarii.
- Am eliminat semnele de punctuație.
- Am șters și spațiile mari dintre cuvinte.
- Am șters comentariile cu o singură literă.
- Am eliminat cuvintele de tip stopwords.
- Am separate cuvintele între ele prin procesul de tokenize.

Am transformat toate cuvintele în text scris cu literă mică, deoarece Python este case sensitive și, de exemplu, dacă am întâlni două cuvinte precum Malta și malta, Python nu ar știi că ele reprezintă același lucru:

Probabil cel mai important punct a fost al patrulea, deoarece în momentul în care se numără caracterele dintr-un text, intră și semnele de punctuație la număr, însă nu sunt semnificative. Pentru majoritatea pașilor am folosit REGEX (Regular expressions). De exemplu, \d se folosește pentru identificarea numerelor, pe care le-am înlocuit cu elementul aflat între ghilimele (’’, adică nimic) prin str.replace. \s+ desemnează mai multe spații, iar în comentarii, acolo unde aveam mai multe spații între cuvinte, le-am înlocuit cu unul singur. Pentru eliminarea semnelor de punctuație, am recurs la ^\w\s, expresie ce identifică elementele dintre cuvinte și spatii, adică semnele de punctuație.
Următorul lucru la fel de important este eliminarea cuvintelor de tip stopwords – acele cuvinte care nu aduc nici o valoare textului, dar, fiind foarte comune, au o frecvență mare de utilizare în cadrul comentariilor. Atunci când renunțăm la ele, numărul de cuvinte se micșorează, iar algoritmii se vor implementa mai rapid (și, în funcție de obiectivul proiectului, putem obține o acuratețe mai mare când vine vorba de clasificarea textului). Aici ne ajutăm de pachetul NLTK pentru a observa care sunt stopwords și pentru a le șterge din comentarii:

Dacă dorim să mai adăugăm cuvinte la lista de mai sus pentru a fi eliminate din text, acest lucru se poate face ușor cu stopwords.update(). Pentru moment, vom lăsa lista așa cum este ea.
Înainte de a merge mai departe, trebuie să menționez că în cadrul NLP există procesele de lemmatize și stemming.
2.1. Stemming
Stemming se referă la reducerea cuvântului la forma lui de bază. Atunci când lucrăm la clasificarea unui document, putem aplica procesul de stemming pentru a analiza subiectul textului respectiv. Cuvintele sunt ‘tăiate’ pentru a reveni la rădăcina lor, ceea ce ajută modele de Machine Learning cu NLP să reducă numărul de cuvinte, iar procesarea să devină mai rapidă.
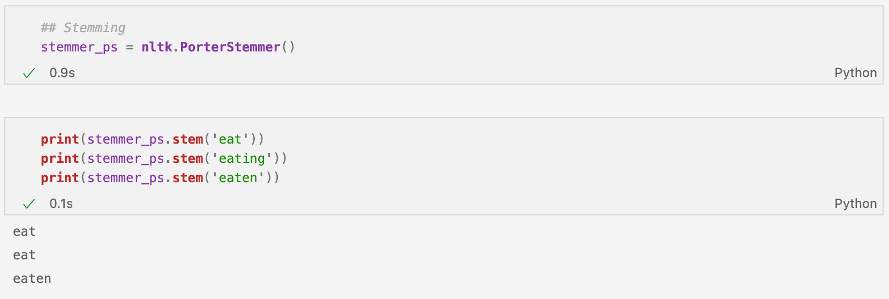
O metodă prin care putem utiliza procesul de Stemming se află și în cadrul pachetului NLTK, prin PorterStemmer. De exemplu, dacă ne uităm la codul de mai jos, observăm cum eat și eating sunt reduse la eat, în timp ce eaten rămâne neschimbat.
Prin funcția de mai jos, luăm cuvintele din coloana tokenized_review, cea care conține lista de cuvinte din comentarii, și aplicăm procesul de stemming:

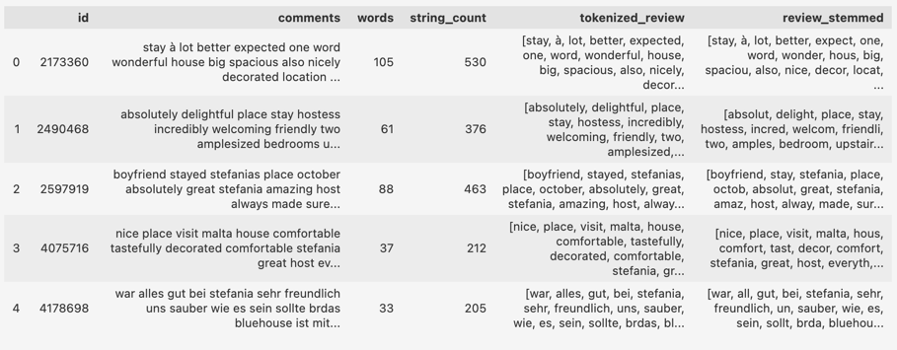
Putem observa cum cum expected s-a transformat în expect, wonderful în wonder, house în hous, spacious în spaciou, nicely în nice, comfortable în comfort sau tastefully în tast. În cazul unor cuvinte – precum tastefully – reducerea lor nu a fost una chiar corectă, deoarece tast, dacă analizăm textul fără să aruncăm un ochi peste context, nu ar avea nici un sens. De aceea, pe lângă stemming, există și procesul de lemmatize.
2.2. Lemmatize
Spre deosebire de stemming, lemmatize este procesul prin care se analizează trăsăturile morfologice, transformând cuvintele de la forma textuală la cea originală, din dicționar, raportându-se la rădăcina acestora. Ca un avantaj, lemmatize ia în calcul și contextul în care află cuvântul, însă toate diferențele acestea față de stemming pot duce și la încetinirea procesului de curățare a cuvintelor. Avem mai jos un exemplu:
Was (cuvânt original) -> be(cuvânt rădăcină), deci convertirea verbului de la trecut la prezent
Pentru început, vom aplica Word Net din cadrul NLTK pentru a vedea cum anume se transformă cuvintele:
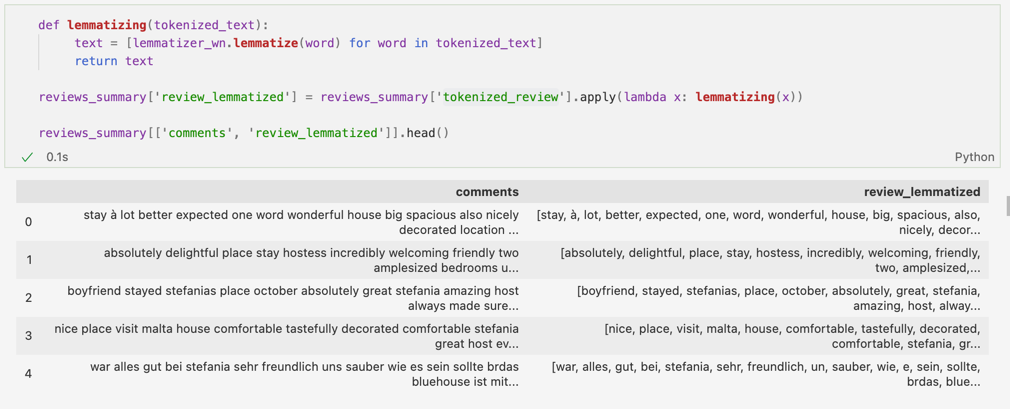
Putem vedea cum exemplul anterior – tastefully – rămăne neschimbat, însă la fel se întâmplă cu majoritatea cuvintelor. Acest fapt reprezintă un dezavantaj, deoarece textul poate rămâne același (sau cu mici diferențe nesemnificative), nefiind nevoie de procesul de lemmatize pentru a-l curăța mai bine. Totuși, acest lucru se întâmplă cu un motiv – nu am aplicat POS tag.
POS vine de la Part of Speech și se referă la asignarea părților de vorbire corespunzătoare cuvintelor din text(da, ca o analiză din clasele primare). Dacă folosim lemmatize fără POS tag, atunci lemmatize va clasifica toate cuvintele drept substantive.
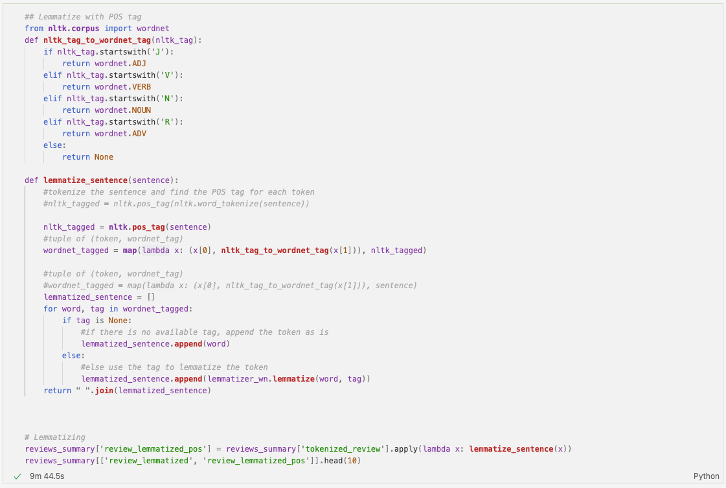
Rezultatul este cel de mai jos:

Putem observa cum better s-a transformat în well, welcoming în welcome sau cum stayed a devenit stay. Diferențele nu sunt foarte multe, însă, spre deosebire de Stemming, cuvintele rezultate sunt corecte. De asemenea, lemmatize poate fi aplicat pentru mai multe limbi, nu doar engleză.
Pentru mai multe informații legate de lemmatize, puteți arunca un ochi pe pagina de aici, pentru a vedea mai multe metode prin care puteți utiliza acest process (WordNet, TextBlob, spaCy, TreeTagger, Pattern, Gensim, Stanford CoreNLP).
3. Top cele mai întâlnite cuvinte
Să mergem puțin mai departe și să începem analiza recenziilor proprietăților din Malta. Pentru început, putem vedea care sunt cele mai des întâlnite cuvinte din comentarii cu ajutorul FreqDist, tot din pachetul NLTK.

Pentru a a vizuliza mai bine rezultatele, am folosit un barchart, pentru a vedea top 10 cuvinte cele mai des întălnite:
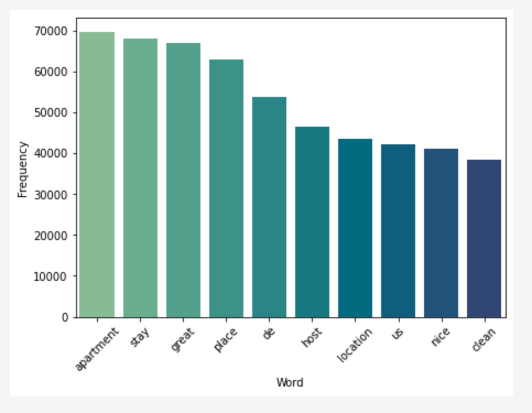
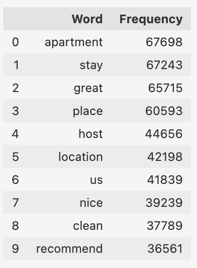
Rezultatul poate fi salvat atât într-un tabel, cât și într-un Word Cloud sau Tree Map. După cum se poate observa, cuvântul cel mai des folosit este ‘apartament’. Acest lucru se corelează cu faptul că cele mai multe locuințe din Malta sunt de tip apartament privat, deci este normal să se afle în top. Următoarele 2 sunt ‘great’ și ‘place’, probabil folosite și ele împreună în cele mai multe cazuri pentru a descrie experiența plăcută de la cazare. Totuși, pentru a vizualiza mai bine cuvintele, ne vom ajuta de un Word Cloud – cu cât cuvintele sunt mai mari, cu atât ele sunt mai des întâlnite în text:

4. Determinarea limbii vorbite
Un alt lucru pe care am vrut să-l testez a fost detectarea limbilor în care au fost scrise recenziile. Cu ajutorul pachetului ‘langdetect’, am identificat următorul top, engleză fiind cea mai folosită, urmată de franceză și germană. Limba franceză se poate observa și-n Word Cloud-ul de mai sus, deoarece multe cuvinte/expresii precum ‘tres bien’, ‘est tres’, ‘de la’ provin din franceză. Funcția pentru detectarea limbii durează destul de mult să ruleze, deci sfatul meu ar fi să salvezi rezultatele, pentru a le avea la îndemână data viitoare când încarci setul de date.
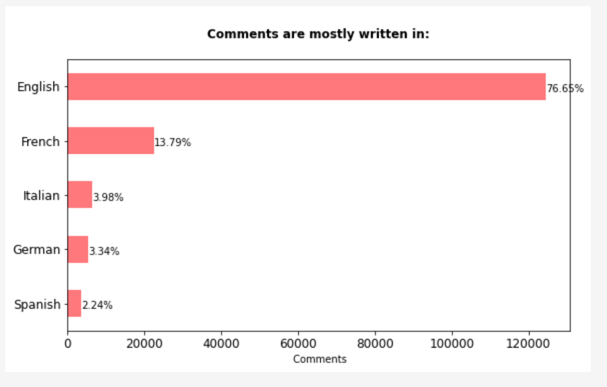
Uitându-mă printre date, am observat cum unele comentarii au fost clasificate la ‘ro’, adică limba română. Totuși, când am verificat cât de corectă este clasificarea, am observat că niciun comentariu nu era în română – textele erau atât de scurte și vagi încât algoritmul nu a știut să le clasifice corect. Majoritatea conțineau un singur cuvânt precum ‘super’, ‘great’, ‘nice’. Ca și medie, numărul de cuvinte folosite in recenzii era de aproximativ 4, probabil de aici și lipsa de date.
Dacă ne rezumăm doar la cuvintele în engleză, atunci topul lor este cel de mai jos:
Înainte să trecem la analiză sentimentelor, felicitări că ai ajuns până aici, nu este cel mai simplu articol de la noi de pe site, dar este unul dintre cele mai practice și cuprinzătoare. Dacă îți dorești să te dezvolți și mai mult în aria de Dată Science (și nu numai) lasă-ne datele tale aici și o să îți trimitem detalii despre programele accelerate pe care le facem pe o multitudine de arii din IT.
5. Sentiment analysis: introducere
Sentiment Analysis sau, tradus în română, analiza sentimentelor, reprezintă procesul prin care un text este analizat cu scopul de afla părerea celui care l-a scris. Aceasta poate să fie pozitivă, negativă sau neutră. Acest tip de analiză este adesea întâlnit în clasificarea recenziilor (fie că este vorba de o cazare, cum este cazul de aici, de un produs Apple sau ultimul film Marvel apărut) sau chiar și al textelor de pe Twitter (există și analize care observă comportamentul utilizatorilor și încearcă să prezică tendințele criptomonedelor, de exemplu). Paragrafele de mai jos reprezintă o introducere a pachetelor care pot fi folosite în Python pentru a afla ce tip de sentiment caracterizează textul.
5.1 Metoda VADER
Bun, am ‘curățat’ recenziile, am analizat cele mai populare cuvinte, le-am transpus în Word Cloud pentru o mai bună vizualizare, am observat în ce limbă sunt scrise majoritatea recenziilor și, pentru a continua, am selectat doar comentariile în engleză. Următorul pas constă în analizarea sentimentelor autorilor. Ce înseamnă acest lucru? Ei bine, fiecare comentariu va fi trecut printr-o funcție din pachetul NLTK și va primi 3 scoruri (pozitiv, negativ, neutru) și unul final (pozitiv, negativ) pentru a determina dacă recenzia este una bună sau negativă. Acest paragraf este doar o introducere în procesul de sentiment analysis, deoarece, într-un proiect de machine learning, scopul final este de a găsi un algoritm bun care să prezică ce tip de text este cel analizat: pozitiv/negativ/neutru. NLTK are deja o metodă pentru analiza sentimentelor numită VADER (Valence Aware Dictionary Sentiment Reasoner).
Mai jos avem un simplu exemplu asupra căruia am aplicat funcția polarity_scores. Ca și output, rezultă un dicționar cu 4 chei cu valorile lor corespunzătoare. Astfel, putem vedea cât de pozitivă, negativă sau neutră este recenzia. Compound Score se calculează însumând primele 3 scoruri și aplicând normalizarea asupra rezultatului – pentru a avea o valoare cuprinsă între -1 și 1. Compound score determină polaritatea sentimentelor: cu cât este mai aproape de 1, sentimentul este unul pozitiv, cu cât este mai aproape de -1, textul este negativ, iar scorurile apropiate de 0 pot indica un text neutru.
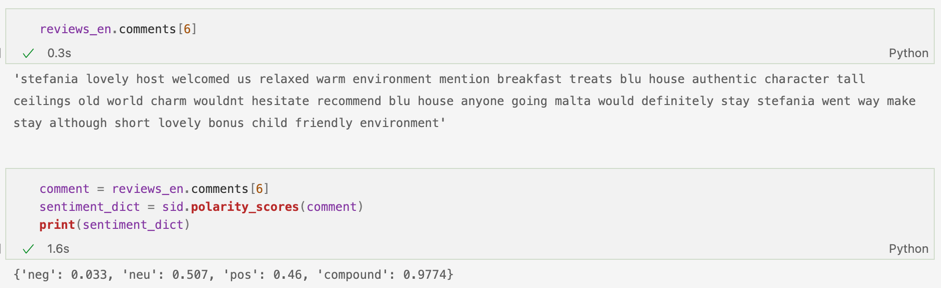
Putem observa cum review-ul de mai sus este unul pozitiv, deoarece conține cuvinte/expresii precum lovely host, warm environment, old world charm, lovely bonus, child friendly environment. Scorul final este aproape de 1 (compound: 0.9774), deci clasificarea textului este corectă. Deși dintre scorurile parțiale cel mai mare aparține sentimentului neutru (50.7%), fiind urmat abia apoi de pozitiv (46%), acest lucru este posibil să fie cauzat de expresia wouldn’t cu conotație negativă, dar, care pusă în context – original provenea de la wouldn’t hesitate to recommend-reprezintă o expresie pozitivă. Astfel, scorul final este cel bun.
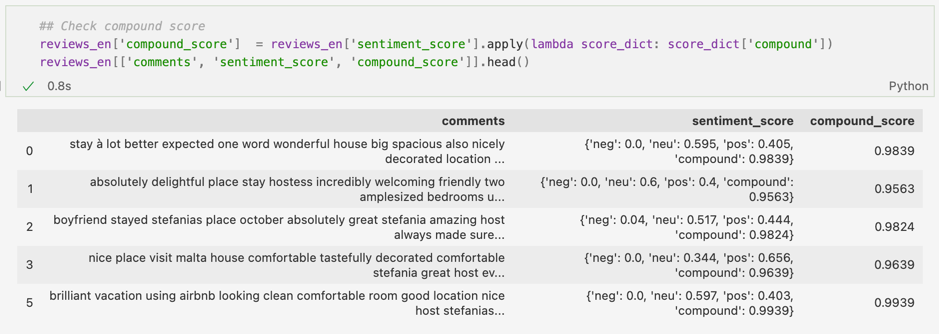
Pentru a vizualiza mai bine compound score, l-am extras într-o coloană separată. După cum se poate vedea mai jos, scorurile apropiate de 1 se potrivesc recenziilor, conținând feedback-uri pozitive:
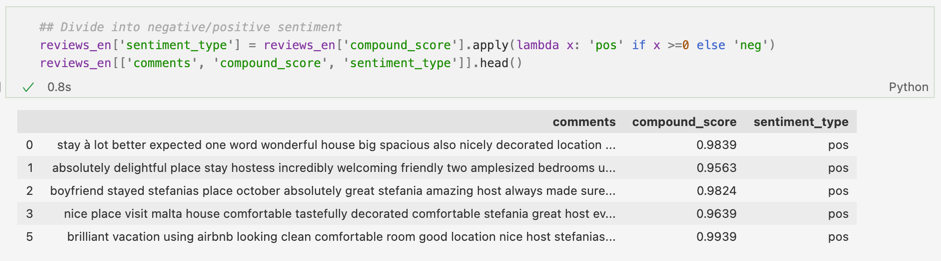
Mai departe, am clasificat scorurile cu compound score mai mare sau egal cu 0 ca fiind pozitive, iar cele situate sub sau egale cu 0 ca fiind negative. Acest threshold (valoarea selectată pentru clasificarea recenziilor) poate fi schimbat și ales în funcție de text și valori – puteam, la fel de bine, să clasific comentariile cu scoruri peste 0.2 ca find pozitive, cele între 0 și 0.2 neutre, iar restul negative.
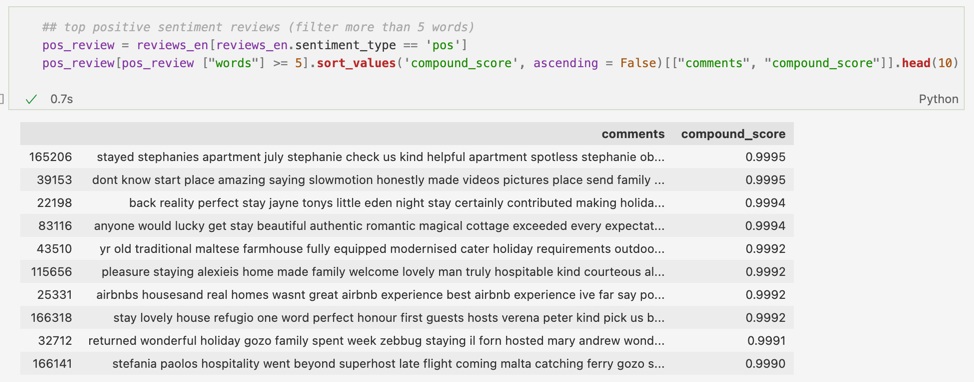
Mai jos am extras top 10 comentarii cu cele mai bune scoruri pozitive:
Iar aici topul comentariilor negative:
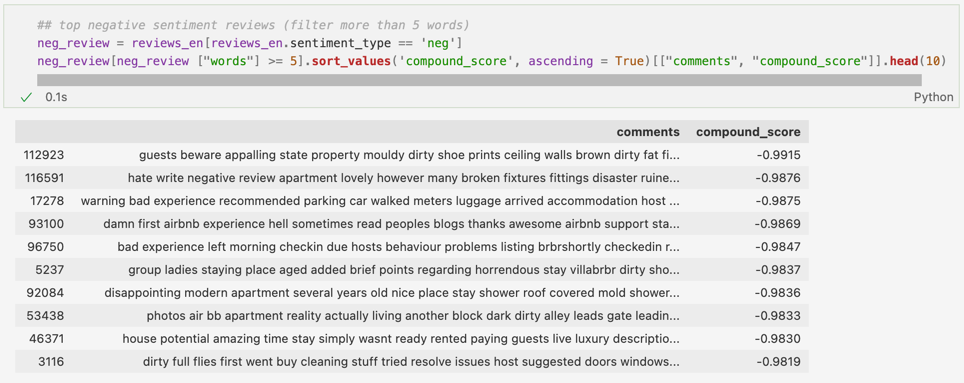
Dacă ne uităm la aceste recenzii negative, observăm cum apar cuvinte precum dirty, hell, bad (experience), warning, disappointing, cuvinte/expresii ce au ajutat algoritmul să le clasifice drept negative.
Deși scorurile finale par a fi bune, există păreri cum că VADER funcționează mai bine pe limbajul folosit în social media, de exemplu pe Twiter, unde comentariile sunt reprezentate de propoziții scurte. Cum recenziile conțin, de obicei, texte mai lungi, am ales să analizez și pachetul TextBlob pentru aflarea polarității sentimentelor.
5.2 TextBlob
TextBlob este o altă librărie Python ce poate fi folosită pentru a înțelege mai bine sentimentele autorilor. Aplicat pe text, TextBlob ne va oferi un scor cu privire la intensitatea sentimentelor, acesta fiind situat între -1 (sentiment negativ) și 1 (sentiment pozitiv). Mai jos am încărcat librăria și am analizat un comentariu aleatoriu. Scorul final este de aproximativ 0.4, deci avem un sentiment pozitiv.

La fel ca și în cazul primei librării, ne putem alege singuri un interval pentru a defini ce înseamnă un sentiment pozitiv, neutru sau negativ. Am plecat de la regula inițială de la textblob, care mi s-a parut și cea mai simplă, și anume tot ce este peste 1 reprezintă un comentariu pozitiv, 0 am ales să îl clasific neutru, iar mai mic decât 0 negativ. Astfel, am testat iar pe un exemplu din cadrul tabelului, un exemplu negativ, pentru a compara cele două scoruri. Ambele au rezultat în numere negative:
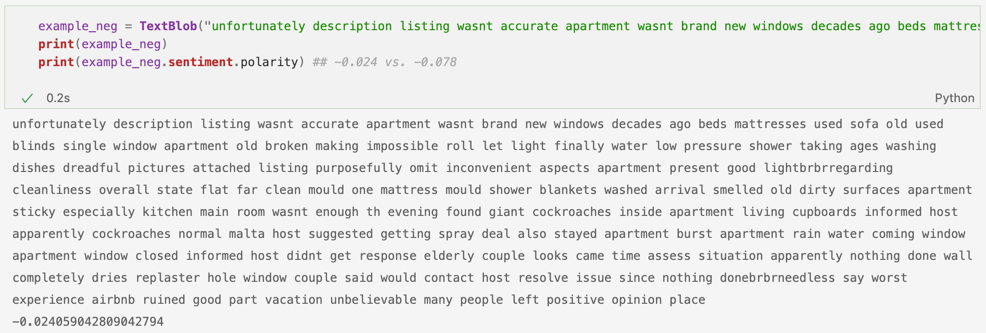
Mai jos avem un exemplu contradictoriu, deoarece VADER a clasificat textul ca fiind ușor negativ, în timp ce TextBlob l-a clasificat pozitiv, deși tot aproape de 0. Dacă ne uităm peste comentariu, putem spune că este unul pozitiv – totuși, cuvintele great și perfect au fost scrise, din greșeală, împreună (probabil un typo neobservat), fapt ce a dus la confuzia primului pachet:

Am mers puțin mai departe și am adăugat încă o coloană setului de date – textblob_score – pentru a face mai ușor o comparație între cele 2 librării. Poți observa în preview-ul de mai jos cum feedback-urile bune legate de cazări au fost clasificate drept pozitive de ambele metode:
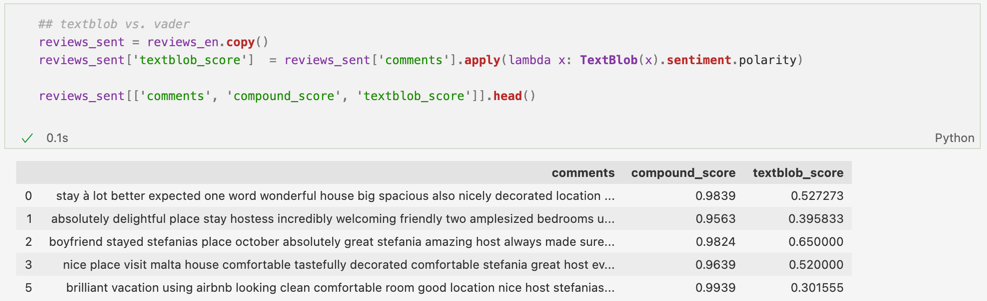
Totuși, așa cum am menționat și mai sus, este vorba doar de câteva exemple, nu de întreg tabelul. Am adăugat un flag (o variabilă) de comparație pentru cele două coloane plecând de la înmulțirea celor două scoruri, iar apoi am asignat 1 pentru rezultate diferite și 0 pentru cele identice (dacă ambele erau pozitive sau dacă ambele erau negative, produsul dintre cele două coloane ar fi dat 1. Dacă un scor era pozitiv, iar celălalt negativ, rezultatul produsului ar fi fost negativ. Așadar, toate rezultatele mai mici decât 0 au fost notate cu 1). De aici, am putut vedea ușor cum 1141 de comentarii au fost clasificate diferit:

Am aruncat o privire la comentariile ce au pus librăriilor mici probleme, pentru a vedea dacă anumiți termerni negativi/pozitivi au înclinat balanța rezultatelor și dacă o librărie s-a descurcat mai bine decât cealaltă. Ca și părere generală, aș putea spune că acolo unde un rezultat era clar pozitiv sau negativ într-o coloană, în cealaltă scorul, deși diferit ca semn, era destul de apropiat de 0. De exemplu, un simplu comentariu precum couldn’t better trip back sure, ce exprimă un sentiment pozitiv, a fost corect clasificat de Textblob, însă compound score-ul de la Vader l-a clasificat drept negativ, însă foarte aproape de 0. Ultimul comentariu legat de good location pool however wasn’t clean reprezintă un comentariu preponderent negativ, nu neapărat neutru, fiind enumerate diverse motive pentru care experiența nu a fost una plăcută. În acest caz, VADER s-a descurcat mai bine decât TextBlob, care l-a clasificat drept pozitiv.
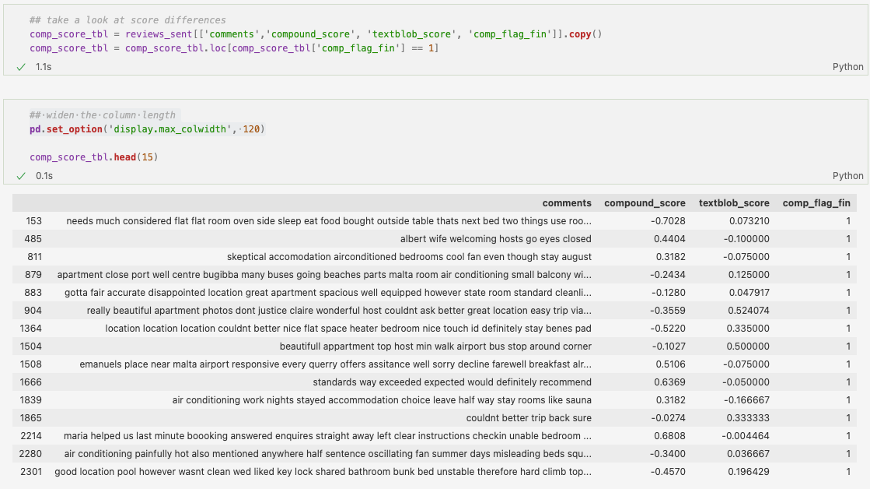
În exemplul de mai jos, am ordonat comentariile în funcție de TextBlob, pentru a vedea care sunt comentariile cu cele mai mici scoruri, conform acestei librării, însă clasificate drept pozitive de cealaltă metodă. Putem observa cum majoritatea textelor sunt pozitive sau cel puțin au o nuanță pozitivă în cuvinte, deși se mai menționează și anumite lucruri ușor negative de către autori. Aici se poate observa ușor cum VADER s-a descurcat mai bine:

Cum spuneam și la început, aceste paragrafe au fost doar o introducere în Sentiment Analysis, o idee cum am putea descifra și înțelege mai bine opiniile, stările și sentimentele persoanelor care au scris recenziile din cadrul AirBnB. Ca și pași următori, ar urma crearea unui model de predicție capabil să analizeze și să clasifice singur textul. Și această etapă este una fun și interesantă, deoarece intrăm mai mult pe partea de modele de Machine Learning, însă acest subiect îl vom aborda cu altă ocazie. Dacă ai ajuns, totuși, până aici, nu pot decât să îți mulțumesc pentru interes și atenție. Sper că ai învâțat ceva nou (în același timp cu mine, deoarece nu am mai lucrat cu NLP până acum), măcar de curiozitate sau poate pentru ce faci la job sau la facultate (poate te-a inspirat pentru un posibil subiect de licență, disertație).
Sumar
- Stabilește obiectivul proiectului tău.
- Întotdeauna curăță datele la început – poți folosi librăria NLKT.
- După curățarea textului, poți încerca analiza acestuia prin Sentiment Analysis. Acest pas te va ajuta să determini sentimentele celor care au scris textele (eu am folosit aici VADER și TextBlob).
- Poți merge mai departe și să încerci să creezi propriul model de clasificare a textului. De obicei se pornește de la un set de date deja clasificat, urmând ca modelul să învețe diverse reguli de grupare pe care le aplică pe un nou set de date.
Toate etapele de mai sus sunt însoțite de research pe internet (articole, bloguri) sau chiar cursuri – am lasăt mai jos, la finalul articolului, link-urile care m-au ajutat pe mine să lucrez la acest proiect. Analiza a fost realizată într-un fișier tip Jupyter Notebook, care poate fi găsit aici. Noi ne putem auzi oricând printr-un mesaj pe LinkedIn, profilul meu fiind acesta.
Bibliografie:
- https://www.geeksforgeeks.org/nlp-how-tokenizing-text-sentence-words-works/?ref=lbp
- https://www.geeksforgeeks.org/python-lemmatization-approaches-with-examples/
- https://machinelearningmastery.com/clean-text-machine-learning-python/
- https://towardsdatascience.com/detecting-bad-customer-reviews-with-nlp-d8b36134dc7e
- https://www.nltk.org/book/ch05.html
- https://livebook.manning.com/book/real-world-machine-learning/chapter-8/25
- https://www.analyticsvidhya.com/blog/2018/10/mining-online-reviews-topic-modeling-lda/
- https://github.com/jonathanoheix/Sentiment-analysis-with-hotel-reviews/blob/master/Sentiment%20analysis%20with%20hotel%20reviews.ipynb
- https://www.machinelearningplus.com/nlp/lemmatization-examples-python/
- https://www.analyticsvidhya.com/blog/2021/10/sentiment-analysis-with-textblob-and-vader/
- LinkedIn Course: NLP with Python for Machine Learning Essential Training








